
What Do We Talk About When We Talk About Context in AI?

If you've spent any time around AI or, more importantly, AI agents recently, you've probably heard the word context used a lot. But depending on where you sit, “context” might mean different things.
Let’s start with something called the context window, which is the working memory of an AI model.

Initially, the context window contains the system’s instructions and a set of tool definitions. Once we start using the agent, it fills with the user’s prompts, the results from running tools, fetched data, and even conversation history.
The context window is the total number of tokens the model can "see" at once: the system prompt, conversation history, tool definitions, retrieved documents, tool results, and the current task. Everything the agent reasons over must fit within this window.
This window is like a box. It has a certain size, and once the box is full, we’re in trouble.
In agent design, context refers to all the information an agent needs to act well. This usually breaks down into a few categories:
- The system prompt: role, rules, and goals that shape behaviour.
- Tools: definitions of what actions the agent can take, such as search, run code, or call APIs, and how to use them.
- Memory: both short-term, meaning the current conversation, and long-term, meaning persisted facts, past interactions, and retrieved knowledge.
- State: the user's request, current data, results of previous steps, and the world the agent is operating in.
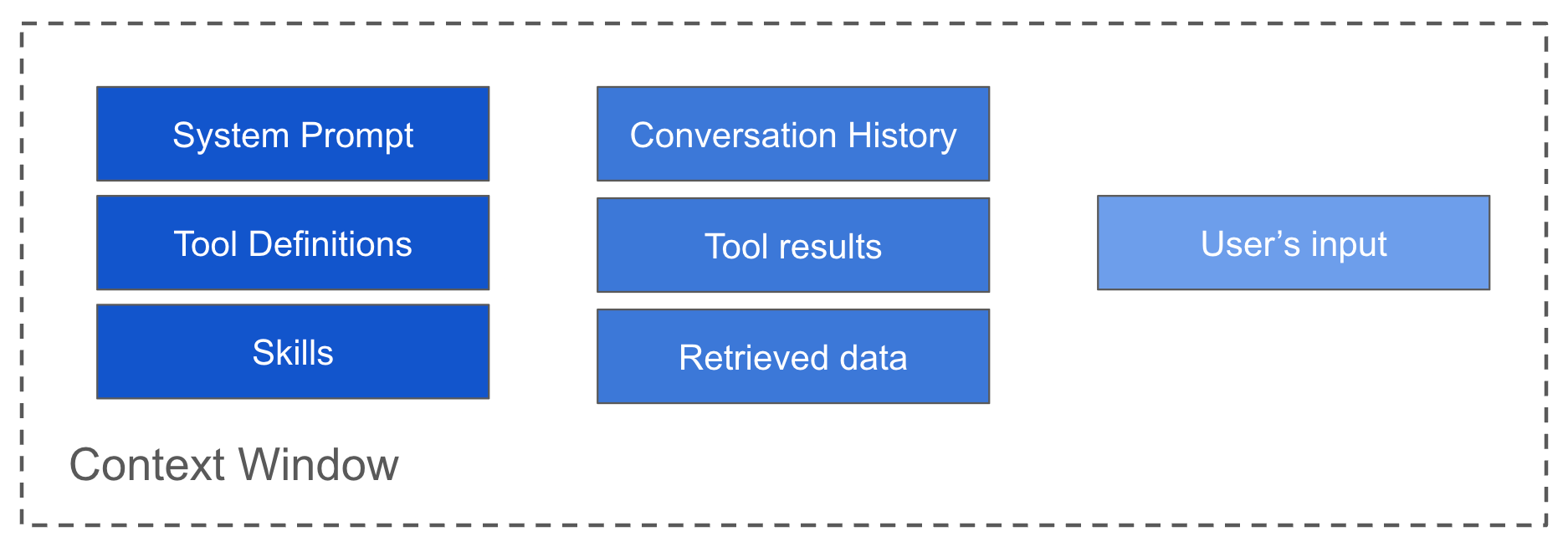
There’s also what we’ve recently started calling Context Engineering: the discipline, or sometimes an art 🙈, of deciding what to put in front of the model at each step so it has exactly what it needs without being overwhelmed by noise.
Too little context and the agent guesses. This is bad. Too much, and it gets distracted. This is even worse.
Context doesn't just happen. You design it.
When we talk with customers, one of the issues we see is that not many people understand how much, or how little, you as a user or developer can manipulate an agent's context. Let me give you an example.
Imagine we’re building an agent that needs to fetch data from a Postgres database. The model generates a tool call, such as “search the database for X”. The tool runs outside the model, in your application code: what we call the agent’s harness. The result returns as a new message appended to the agent’s conversation, what we normally call a “tool result”.
The model then reads that result, just like it reads everything else. The data the agent fetched is now in the context window and stays there for the rest of the conversation, until it's dropped or summarised.
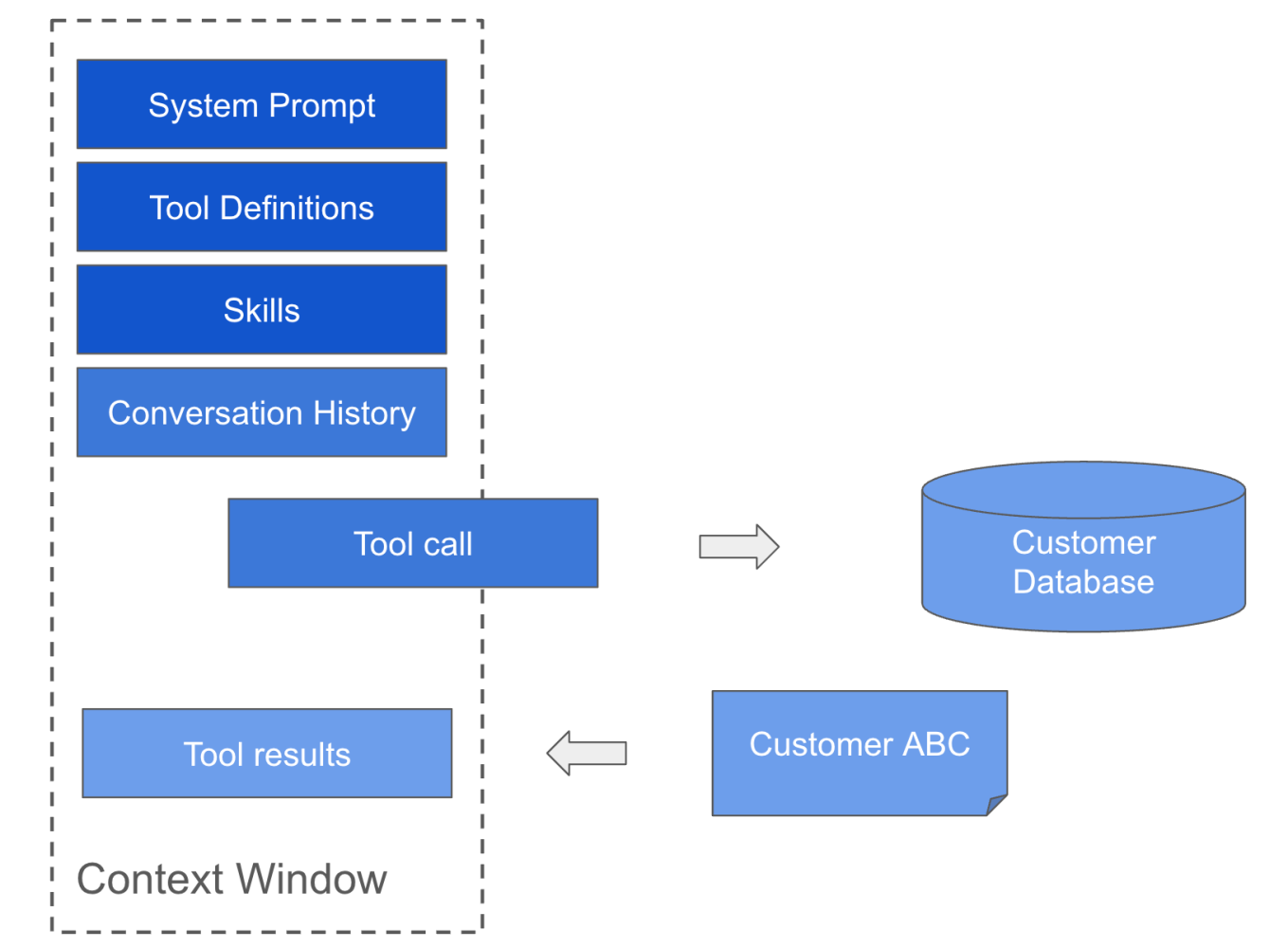
If an agent calls a tool that returns 10,000 rows of JSON, all 10,000 rows are added to the context. This consumes a lot of tokens.
Have we talked about the token budget yet? No? Let me put it like this: it costs money. On that call and on every subsequent turn. Did you know that the whole chat history gets re-sent each time?
As we said earlier, adding too much information often makes the model worse: it gets distracted by noise or loses track of the actual task.
We call this Context Rot, or context pollution.
Preventing Context Rot
Is there anything we can do to minimise these situations? Yes. And these are the things that, when you put them together, form what we call Context Engineering.
These are a few patterns you want to consider when building an agent, or a harness:
- Return less at the tool boundary. The tool fetches 10,000 rows but returns a summary, the top five, or just the answer to the question. The filtering happens in your agent’s code before anything reaches the model.
- Keep the data external and pass a reference. The tool writes results to a file or a variable in the execution environment, and only a pointer, such as “saved to results.csv, 10k rows, columns: …”, is included in the context. The agent can then act on it without ever ingesting it.
- Code execution / code mode. Instead of the model reading data and reasoning over it token by token, it writes code that processes the data in a sandbox. The bulk of the data lives in the runtime, and only the final computed result is sent to the context. This is dramatically more efficient for anything data-heavy.
- Pagination and progressive disclosure. Fetch pages one at a time, or fetch metadata first, pulling the full payload only when the agent decides it's needed.
At this point, I’m sure you have heard the deterministic/non-deterministic story several times. However, it’s important to remember that as engineers building an agent, we now have something that can decide for us.
We just need to provide the options that let the agent make its own decisions, which is the whole point of building an autonomous agent.
Let me give you a more concrete example. We have built a tool that provides data to the agent. That tool fetches data, as you expect, but when we return it, we add metadata that tells the agent, or the model, what to do next.
For results that are larger than a certain size, we send a message to the model indicating that the result is too large. We recommend reviewing the schema, which is included in the metadata, to see whether a new request filtering out some fields would be better, or perhaps making a more precise request by adding more conditions.
Don’t get lost in the details. The most important thing is not the exact implementation, but providing options for the agent and the model to do the right thing. This is what Context Engineering is about.
Let’s talk
Context Engineering is still an emerging discipline, but it is quickly becoming one of the most important aspects of building reliable AI agents. The models will continue to improve, but how we manage what they see, remember, and reason over will remain a critical part of system design.
If you're building agents or exploring where they can create value in your business, we at TAVON.ai would love to talk. Reach out to discuss your use case, compare notes, or learn how we're approaching Context Engineering in production systems.